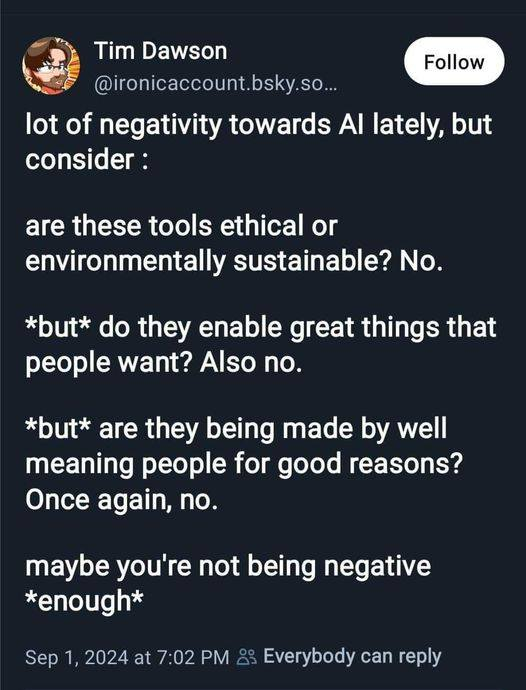
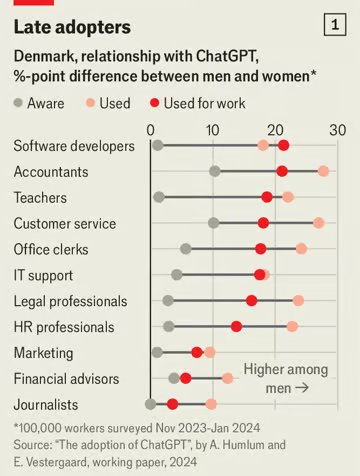
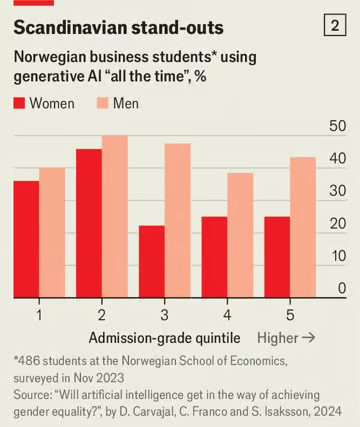
SO, it started quite nicely with a fully working program. However nearing the end... or at the end of my programming experience or asking it to program something for me, it wrote in some nasty nasty screen flickering shit. I couldn't stop it and it quickly just froze my screen where the only option was to push the button. I tried it a second time to confirm, but this time I was able to quickly go to a different CLI window and kill that sonobabich. Here is what it came up with in case you want to try it. maybe it only screws up my computer:
import os
import cv2
import numpy as np
import time
import tkinter as tk
from tkinter import messagebox, filedialog
def threshold_to_black(image_path, duration):
original_image = cv2.imread(image_path)
if original_image is None:
print("Error: Could not read the image.")
return
height, width, _ = original_image.shape
gray_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2GRAY)
steps = duration * 10 # 10 frames per second
for i in range(steps + 1):
# Calculate the threshold value (0 to 255)
threshold = int((i / steps) * 255)
# Create the thresholded image
thresholded_image = np.where(gray_image < threshold, 0, 255).astype(np.uint8)
# Resize the thresholded image to fill the window
resized_image = cv2.resize(thresholded_image, (window_width, window_height), interpolation=cv2.INTER_LINEAR)
# Display the thresholded image
cv2.imshow(window_name, resized_image)
# Wait for a short period to create the effect
time.sleep(0.1)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Display the final black image
cv2.imshow(window_name, np.zeros_like(thresholded_image))
while True:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
def select_image():
current_directory = os.getcwd() # Get the current directory
filetypes = (
('JPEG files', '*.jpg'),
('JPEG files', '*.jpeg'),
('All files', '*.*')
)
filename = filedialog.askopenfilename(
title='Select an Image',
initialdir=current_directory, # Start in the current directory
filetypes=filetypes
)
if filename:
return filename
else:
messagebox.showerror("Error", "No image selected.")
return None
def get_duration():
def submit():
nonlocal total_duration
try:
minutes = int(minutes_entry.get())
seconds = int(seconds_entry.get())
total_duration = minutes * 60 + seconds
if total_duration > 0:
duration_window.destroy()
else:
messagebox.showerror("Error", "Duration must be greater than zero.")
except ValueError:
messagebox.showerror("Error", "Please enter valid integers.")
total_duration = None
duration_window = tk.Toplevel()
duration_window.title("Input Duration")
tk.Label(duration_window, text="Enter duration:").grid(row=0, columnspan=2)
tk.Label(duration_window, text="Minutes:").grid(row=1, column=0)
minutes_entry = tk.Entry(duration_window)
minutes_entry.grid(row=1, column=1)
minutes_entry.insert(0, "12") # Set default value for minutes
tk.Label(duration_window, text="Seconds:").grid(row=2, column=0)
seconds_entry = tk.Entry(duration_window)
seconds_entry.grid(row=2, column=1)
seconds_entry.insert(0, "2") # Set default value for seconds
tk.Button(duration_window, text="Submit", command=submit).grid(row=3, columnspan=2)
# Center the duration window on the screen
duration_window.update_idletasks() # Update "requested size" from geometry manager
width = duration_window.winfo_width()
height = duration_window.winfo_height()
x = (duration_window.winfo_screenwidth() // 2) - (width // 2)
y = (duration_window.winfo_screenheight() // 2) - (height // 2)
duration_window.geometry(f'{width}x{height}+{x}+{y}')
duration_window.transient() # Make the duration window modal
duration_window.grab_set() # Prevent interaction with the main window
duration_window.wait_window() # Wait for the duration window to close
return total_duration
def wait_for_start(image_path):
global window_name, window_width, window_height
original_image = cv2.imread(image_path)
height, width, _ = original_image.shape
window_name = 'Threshold to Black'
cv2.namedWindow(window_name, cv2.WINDOW_NORMAL)
cv2.resizeWindow(window_name, width, height)
cv2.imshow(window_name, np.zeros((height, width, 3), dtype=np.uint8)) # Black window
print("Press 's' to start the threshold effect. Press 'F11' to toggle full screen.")
while True:
key = cv2.waitKey(1) & 0xFF
if key == ord('s'):
break
elif key == 255: # F11 key
toggle_fullscreen()
def toggle_fullscreen():
global window_name
fullscreen = cv2.getWindowProperty(window_name, cv2.WND_PROP_FULLSCREEN)
if fullscreen == cv2.WINDOW_FULLSCREEN:
cv2.setWindowProperty(window_name, cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_NORMAL)
else:
cv2.setWindowProperty(window_name, cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
if __name__ == "__main__":
current_directory = os.getcwd()
jpeg_files = [f for f in os.listdir(current_directory) if f.lower().endswith(('.jpeg', '.jpg'))]
if jpeg_files:
image_path = select_image()
if image_path is None:
print("No image selected. Exiting.")
exit()
duration = get_duration()
if duration is None:
print("No valid duration entered. Exiting.")
exit()
wait_for_start(image_path)
# Get the original