LocalLLaMA
2200 readers
5 users here now
Community to discuss about LLaMA, the large language model created by Meta AI.
This is intended to be a replacement for r/LocalLLaMA on Reddit.
founded 1 year ago
MODERATORS
1
2
3
4
15
Are there any good open source text-to-music models, preferably with lyrical abilities?
(lemmy.dbzer0.com)
5
Another day, another model.
Just one day after Meta released their new frontier models, Mistral AI surprised us with a new model, Mistral Large 2.
It's quite a big one with 123B parameters, so I'm not sure if I would be able to run it at all. However, based on their numbers, it seems to come close to GPT-4o. They claim to be on par with GPT-4o, Claude 3 Opus, and the fresh Llama 3 405B regarding coding related tasks.
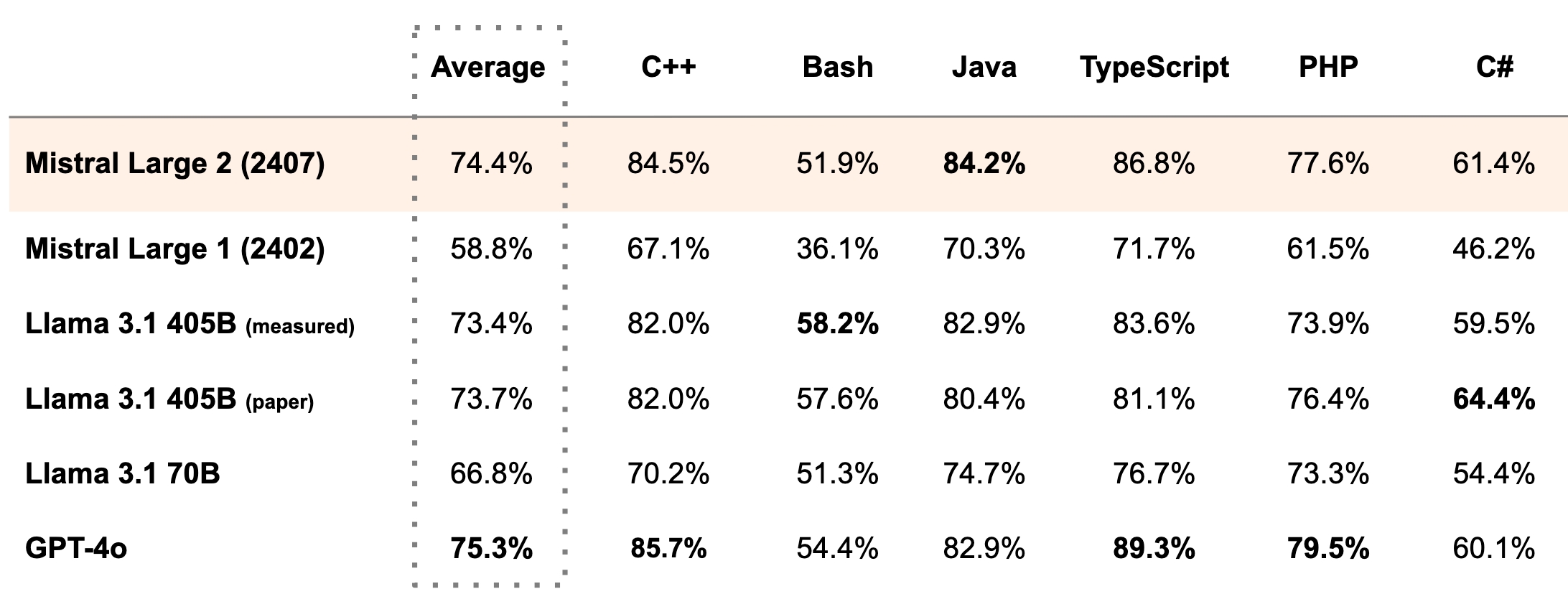
It's multilingual, and from what they said in their blog post, it was trained on a large coding data set as well covering 80+ programming languages. They also claim that it is "trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer"
On the licensing side, it's free for research and non-commercial applications, but you have to pay them for commercial use.
6
7
8
9
10
11
12
14
14
Looking for upgrade advice. Anyone building their supercomputer out of 3060s?
(discuss.tchncs.de)
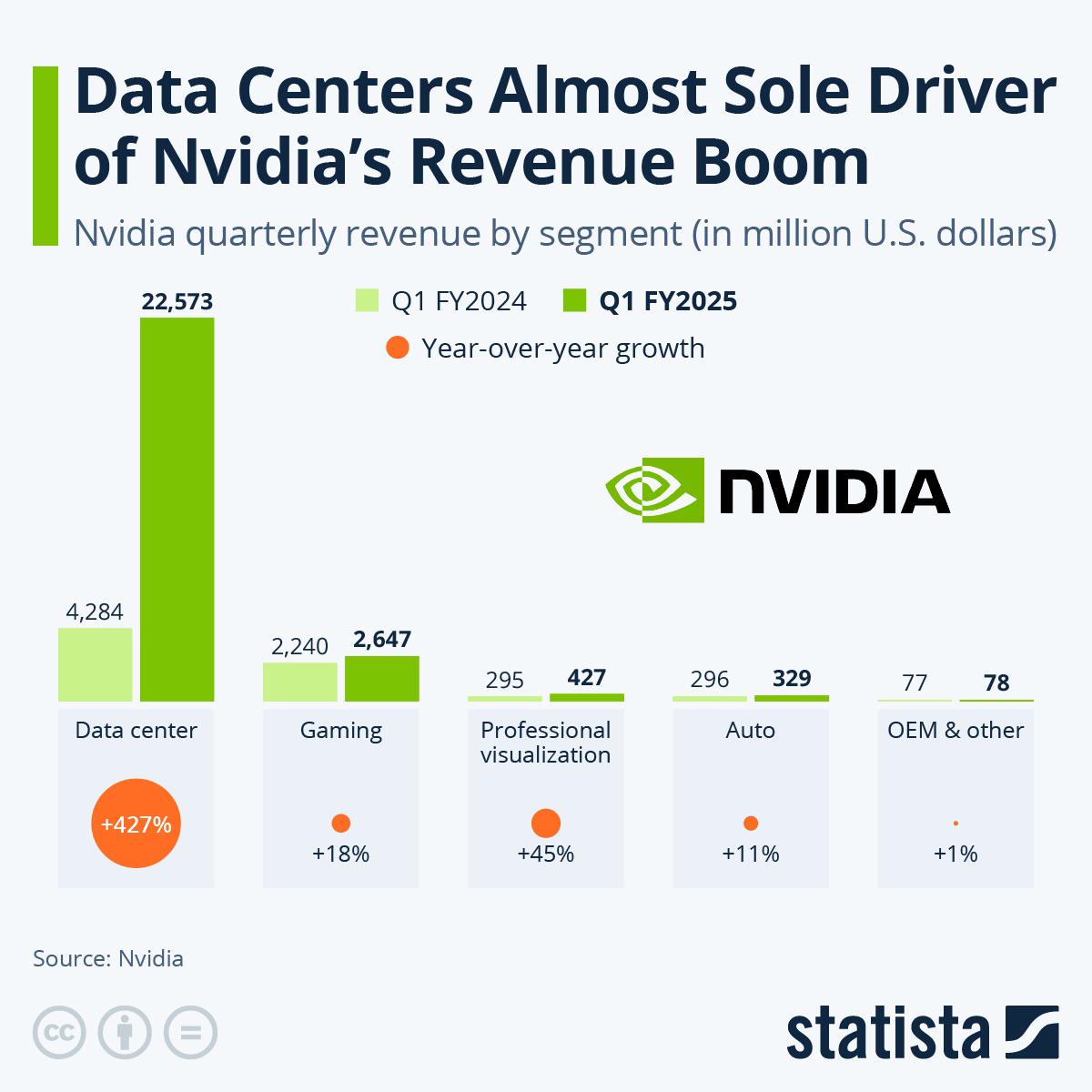
So here's the way I see it; with Data Center profits being the way they are, I don't think Nvidia's going to do us any favors with GPU pricing next generation. And apparently, the new rule is Nvidia cards exist to bring AMD prices up.
So here's my plan. Starting with my current system;
OS: Linux Mint 21.2 x86_64
CPU: AMD Ryzen 7 5700G with Radeon Graphics (16) @ 4.673GHz
GPU: NVIDIA GeForce RTX 3060 Lite Hash Rate
GPU: AMD ATI 0b:00.0 Cezanne
GPU: NVIDIA GeForce GTX 1080 Ti
Memory: 4646MiB / 31374MiB
I think I'm better off just buying another 3060 or maybe 4060ti/16. To be nitpicky, I can get 3 3060s for the price of 2 4060tis and get more VRAM plus wider memory bus. The 4060ti is probably better in the long run, it's just so damn expensive for what you're actually getting. The 3060 really is the working man's compute card. It needs to be on an all-time-greats list.
My limitations are that I don't have room for full-length cards (a 1080ti, at 267mm, just barely fits), also I don't want the cursed power connector. Also, I don't really want to buy used because I've lost all faith in humanity and trust in my fellow man, but I realize that's more of a "me" problem.
Plus, I'm sure that used P40s and P100s are a great value as far as VRAM goes, but how long are they going to last? I've been using GPGPU since the early days of LuxRender OpenCL and Daz Studio Iray, so I know that sinking feeling when older CUDA versions get dropped from support and my GPU becomes a paperweight. Maxwell is already deprecated, so Pascal's days are definitely numbered.
On the CPU side, I'm upgrading to whatever they announce for Ryzen 9000 and a ton of RAM. Hopefully they have some models without NPUs, I don't think I'll need them. As far as what I'm running, it's Ollama and Oobabooga, mostly models 32Gb and lower. My goal is to run Mixtral 8x22b but I'll probably have to run it at a lower quant, maybe one of the 40 or 50Gb versions.
My budget: Less than Threadripper level.
Thanks for listening to my insane ramblings. Any thoughts?
15
16
17
18
20
21
22
23
24
25
view more: next ›